Introduction to Linear Regression
BigML’s upcoming release on Thursday, March 21, 2019, will be presenting our latest resource to the platform: Linear Regressions. In this post, we’ll do a quick introduction to General Linear Models before we move on to the remainder of our series of 6 blog posts (including this one) to give you a detailed perspective of what’s behind the new capabilities. Today’s post explains the basic concepts that will be followed by an example use case. Then, there will be three more blog posts focused on how to use Linear Regression through the BigML Dashboard, API, and WhizzML for automation. Finally, we will complete this series of posts with a technical view of how Linear Regressions work behind the scenes.
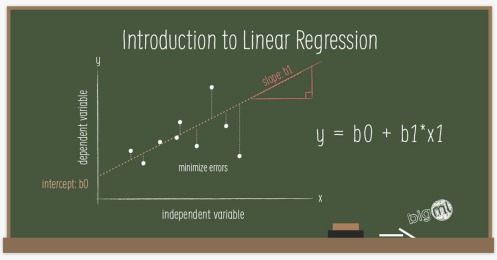
Understanding Linear Regressions
Linear Regression is a supervised Machine Learning technique that can be used to solve, you guessed it, regression problems. Learning a linear regression model involves estimating the coefficients values for independent input fields that together with the intercept (or bias), determine the value of the target or objective field. A positive coefficient (b_i > 0), indicates a positive correlation between the input field and the objective field, while negative coefficients (b_i < 0) indicate a negative correlation. Higher absolute coefficient values for a given field can be interpreted to have a greater influence on final predictions.
By definition, the input fields (x_1, x_2, …, x_n) in the linear regression formula need to be numeric values. However, BigML linear regressions can support any type of fields by applying a set of transformations to categorical, text, and items fields. Moreover, BigML can also handle missing values for any type of field.
It’s perhaps fair to say linear regression is the granddaddy of statistical techniques that is required reading for any Machine Learning 101 student as it’s considered a fundamental supervised learning technique. Its strength is in its simplicity, which also implies it is pretty easy to interpret vs. most other algorithms. As such, it makes for a nice quick and dirty baseline regression model similar to Logistic Regression for classification problems. However, it is also important to grasp those situations linear regression may not be the best fit, despite its simplicity and explainability:
- It works best when the features involved are independent or to put it another way less correlated with one another.
- The method is also known to be fairly sensitive to outliers. A single data point far from the mean values can end up significantly affecting the slope of your regression line, in turn, hurting the models chances to better generalize come prediction time.
Of course, using the standardized Machine Learning resources on the BigML platform, you can mitigate these issues and get more mileage from the subsequent iterations of your Linear Regressions. For instance,
- If you have many columns in your dataset (aka a wide dataset) you can use Principal component analysis (PCA) to transform such a dataset in order to obtain uncorrelated features.
- Or, by using BigML Anomalies, you can easily identify and remove the few outliers skewing your linear regression to arrive at a more acceptable regression line.
Here’s where you can find the Linear Regression capability on the BigML Dashboard: 
Want to know more about Linear Regressions?
If you would like to learn more about Linear Regressions and find out how to apply it via the BigML Dashboard, API or WhizzML please stay tuned for the rest of this series of blogs posts to be published in the next week.
The Official Blog of BigML.com published first on The Official Blog of BigML.com
No comments:
Post a Comment